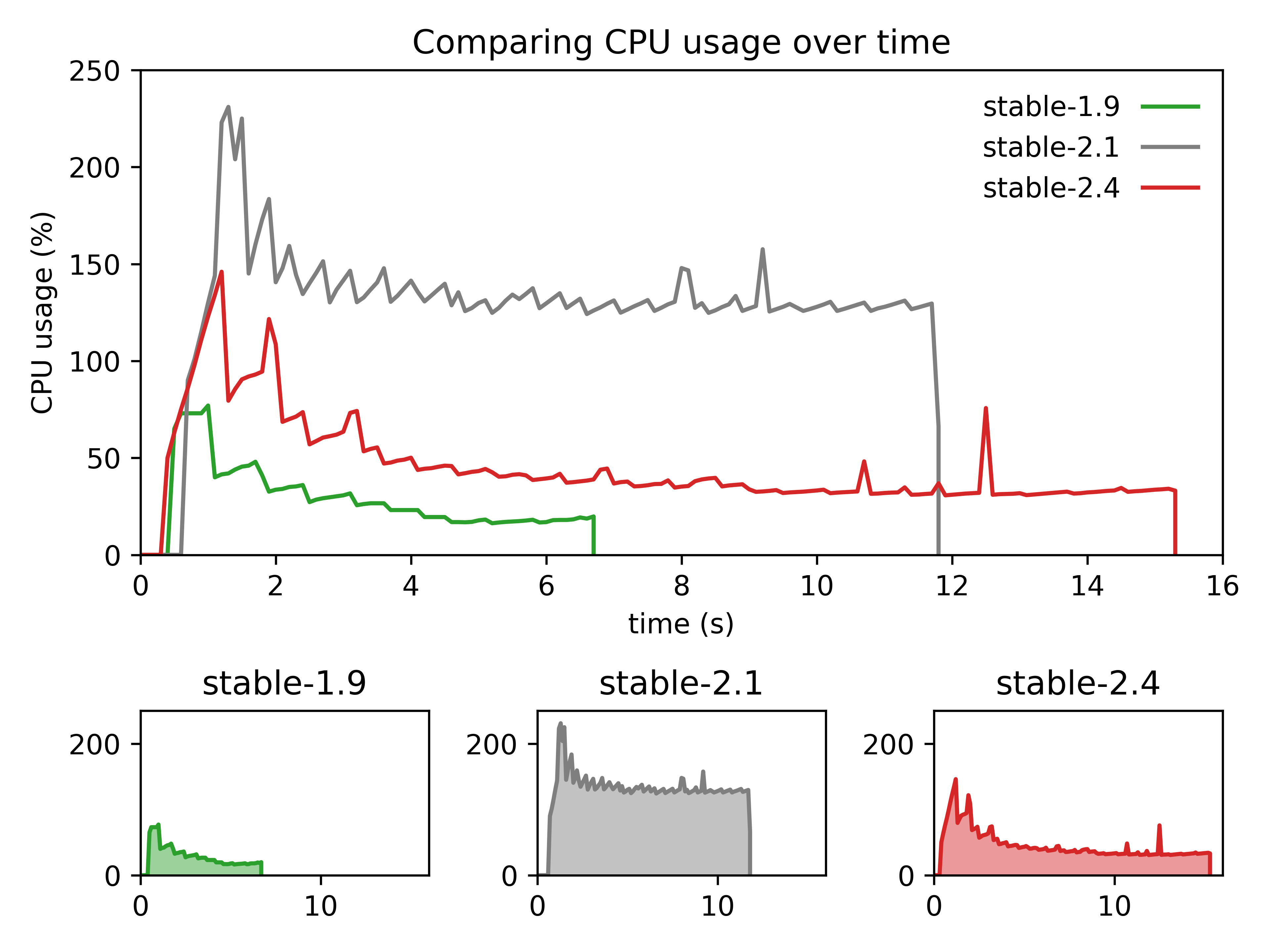
Since Ansible switched to v2, the deep rebuild of its architecture has led to a huge slowdown in its performance, which is still far from being fully addressed in the current state of the devel branch: for instance,
a playbook from
SlapOS (on which relies
Teralab), containing hundreds of task (with many of them being skipped), runs
-
with version stable-1.9 in about 6.8s @ 28% average CPU load,
-
with version stable-2.1 in about 11.9s @ 127% average CPU load (i.e. x7.9 slower than version stable-1.9), and
-
with version stable-2.4 in about 15.4s @ 45% average CPU load (i.e. x3.6 slower than version stable-1.9)
(no other process with significant CPU usage is running in the background; playbook runs on localhost only).
The issue arises from the way Ansible loops over the tasks to perform and the hosts to reach: for each task, it loops over the hosts list; for each host, it adds in the task queue a new sub-process in charge of executing the current task on the current host (technically, there is a limited number of workers - i.e. sub-processes - that can be queued at the same time).
In order to execute it, this sub-process launches a few commands on the host, including a call to python, to run a templated script. The performance issue mainly relies on the fact that the python interpreter exits after the script has run; a new python call will be required the next time a task will have to be executed on that host.
The details of the transaction between the host and the remote are actually not contributing to the performance issue but for the sake of completeness the idea is roughly the following: the remote machine selects in its library the necessary modules to perform the task at hand, it zips, encodes and integrates them in a template file that is then copied to the host. This templated file is a python script containing the zipped and encoded module as a string: it first decodes and unzips the necessary module (write to disk in a temporary repo) and next launches this module with the needed parameters in order to execute the task it has to do.
There are actually two main issues:
As mentioned, the first one is the fact that each time a task is executed on a host, it requires to launch a fresh python interpreter. This issue is addressed using the Mitogen's plugin for Ansible that bypasses in its strategy the launch of one python per task; python is maintained alive (sleeping) in between two tasks.
This reduces the execution time of the early mentioned playbook with Ansible version stable-2.4 to about 8.5s @ 67% average CPU load (i.e. x3.0 slower than version stable-1.9).
The second issue is actually an issue only under certain circumstances: as long as there is only one host to reach (it includes our use case in which the only host to reach is localhost), the task queue contains only one worker (since the queue is cleaned before moving on to the next task, ensuring that all the hosts have completed the current task before anyone moves on to the next) and, hence, there is no need to detach a sub-process to handle this task in the background (since the only thing to do in the meantime is to wait for the queue to be cleaned). Thus, one can easily save the time needed to fork the sub-process.
Note: forking a sub-process may be useful to drain on the main process the results of the task running in the background; however, in our situation, it turns out that this does not represent a time saving sufficient to balance the cost of forking a sub-process.
This issue can be addressed using a simple hack that does not break at all the Ansible's behaviour in more general contexts and only requires a small modification in the code: as stated, this issue is related to the core of any strategy; more precisely
when the current task is added in queue: @
lib/ansible/plugins/strategy/__init__.py:_queue_task replace
worker_prc.start()
with
if len(self._workers) > 1:
worker_prc.start()
else:
# this hack bypasses the forking of a sub-process if there is only one worker; reduces the execution time
worker_prc.run()
Note: .start() is a method of Process from multiprocessing (whose worker_prc is an instance of a sub-class) that forks a new sub-process and call the .run() method in the newly created context (.run() is overridden by the sub-class and is in charge to do the job). Directly calling .run() allows one to bypass the fork of a sub-process and directly runs the code in the current context.
In addition to using Mitogen, this reduces the execution time of the early mentioned playbook with Ansible version stable-2.4 to about 6.5s @ 76% average CPU load (i.e. still x2.6 slower than version stable-1.9).
Note: in order to have this fix applied in production asap, it has been implemented in a fork of Mitogen instead of Ansible (Mitogen applies a monkey-patch on Ansible's linear strategy by sub-classing and allows us to override the Ansible's core function _queue_task).
The following figure summarizes the impact of the proposed improvements while running the same playbook as earlier:
Conclusion: there is still more CPU load than what was achieved in version stable-1.9 but, at least, the execution time looks more similar.